As ever when I’ve written something long and vaguely serious, I can’t think of anything to talk about for days afterwards. So to try and break me back into the writing habit, I’m going to talk a bit about the response that Discussion and Citation in the Blogosphere has received. As NSLog() has pointed out, it’s not the most revolutionary of posts, but I think sometimes it’s still important to state what we believe to be obvious – either to have it challenged or because other people don’t find it obvious. I think both types of reaction have taken place in this particular case.
(1) A few responses to comments
I’m going to start off by looking at a couple of the comments that I received about the piece. Jumping right in, these were (1) that I didn’t talk about the kind of indented hierarchical threaded-discussion boards (in which discussion can take a much more non-linear approach than my diagram suggested) and that (2) my diagram of micro-paradigm shifts was too neat and doesn’t mirror reality (Microdocs).
Firstly I’d like to say straight-away that they are – of course – both right. Real-life is always messier than abstractions, and I could never hope to have talked about all the kinds of online discussion boards that exist.
In the case of the indented-threading models – all I can say in my defence was that the piece I was trying to write wasn’t so much about the directionality or linearity of message-board discussions, but more about the filtering mechanisms implicit in the system. Another commentator) also pointed out that some message-board systems allow trackback on individual posts. Here I can only say that there’s a certain degree of bifurcation going on there – I can’t see a way in which those people within the social system of the board itself can help the filtering process for strangers, except by moving outside it and linking to it from outside (say from a weblog). And he also talks about weblog / message-board hybrids – which again I can only say that I wasn’t specifically familiar with. There are a lot of interesting models for online fora – and I hope people forgive me for concentrating for the most part on the one that the most people are familiar with… I think the most important thing that I want to say about this stuff is that I was definitely not undermining the importance of message-board technology in community-building. I’m a dyed-in-the-wool advocate of message-boards and have been playing with some new models in moderation and administration over at Barbelith Underground for several years now.
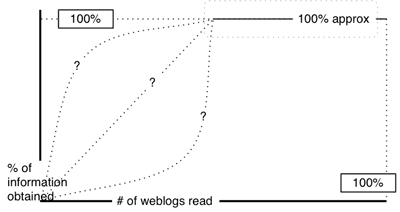
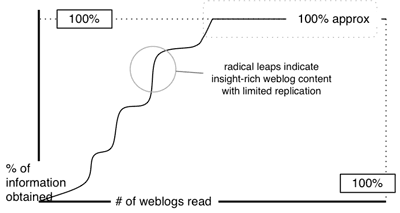
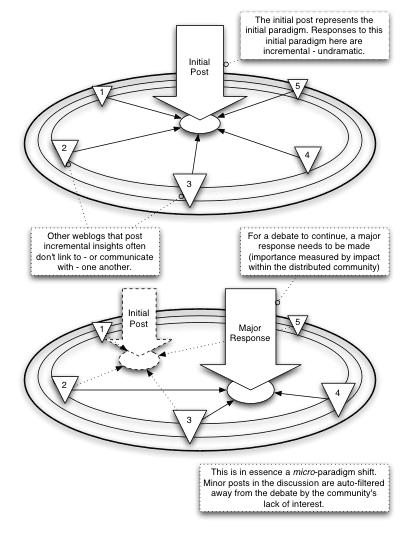
As regards my diagram being too regular and not reflecting reality (again cf. Microdoc’s diagram of this debate)- where they see difference – I see considerable similarity. Let’s call those posts that have one or less inward link “supporting” posts, and all those with more than one “structural” posts. If one does this, then even at this early stage it’s clear that only a couple of posts are driving the discussion forward. At the moment the debate has bifurcated (I specifically mention that as a possibility in the last post) – and no doubt one of those will be taken further by a subsequent structuring posts at some point. While the reality will always be messier than the abstracted diagram, I believe that (if we give the debate time enough to develop) the two diagrams will come to look more and more similar.
(2) On parallels with academic citation networks
Now I’m going to turn to another common response to the post. A few people have argued that (i) the existence of peer review mechanisms and (ii) an expertise-based barrier of entry makes academic filtering mechanisms very different from weblogging ones. I’ve seen this position articulated on a few sites – particularly 2lmc, commonplaces and a comment by Ross Mayfield on Many to Many – but I’m going to concentrate (yet again) on the response from Microdoc because it’s the most succinct and clear:
There is a substantial difference between writing an academic paper and having it published in comparison to blogging. In the academic world, I write a paper, have my peers review it, and then I submit it for publication where it may go through another review process, and eventually be published and it is from that paper that has two or three reviews that people will cite in their papers. That is, the academic paper is already “authorized” or “reviewed” and therefore has some weight already.
This is certainly true – there is a substantial barrier to entry in writing academic work. You have to be (to an extent at least) an expert in your field before your words will be seen by the rest of the community. And that means you also have to be an expert in your field before you can cite another article as well (although you don’t have to have the same level of expertise in the field of the article that you’ve cited).
But once you are inside that community of people, what then? Articles are not cited an equal number of times and nor are they given same value within the community – these mechanisms of citation and linkage appear to occur in almost exactly the same way as within weblogs. Individual scholars choose who to cite through a complex balancing act of who they wish to credit to, who directly inspires them, who they have to employ to back up their arguments and which articles have achieved such value and ubiquity that you can’t have a discussion about a given subject without citing them (this last one is more common among graduate students persuing a doctorate). Some of these citations consist of nothing more than a vote – a gesture that the article concerned is pertinent to a discussion. Often articles (or books) crystallise a discussion and are treated as a baseline from then on.
Essentially – the only difference that having barriers to entry into the community makes is that the criteria for judging whether a piece of writing is worth linking to may be different. The mechanisms, however, remain identical. Certain articles get cited, others do not. Discussion happens in a series of discontinuous leaps – sometimes collapsing back onto itself, sometimes bifurcating – with the community self-filtering the good stuff to where it’s most likely to be seen.
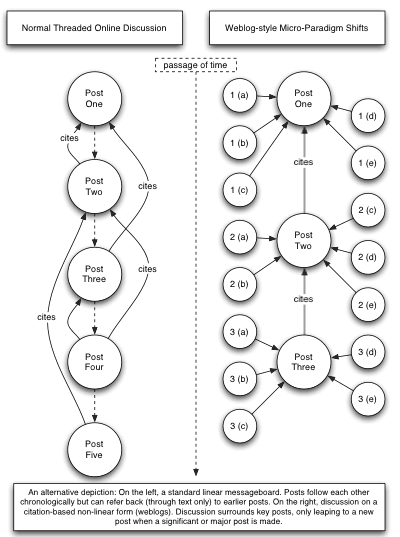 On the left, you can see a normal piece of discussion – as it would occur on a threaded message-board. In this example, the top post is the first, the second post cites the first, the third also cites the first while the fourth cites both the third and the second but not the first. In this debate there is no filtering mechanism of any kind. If the second post is entirely off-topic or contains spurious information, then it remains very clearly in the context of the thread. And if that thread is linked to from elsewhere, there can be no simple evaluation of what posts are considered more worthwhile than other1 – the thread is either good or it is not.
On the left, you can see a normal piece of discussion – as it would occur on a threaded message-board. In this example, the top post is the first, the second post cites the first, the third also cites the first while the fourth cites both the third and the second but not the first. In this debate there is no filtering mechanism of any kind. If the second post is entirely off-topic or contains spurious information, then it remains very clearly in the context of the thread. And if that thread is linked to from elsewhere, there can be no simple evaluation of what posts are considered more worthwhile than other1 – the thread is either good or it is not.