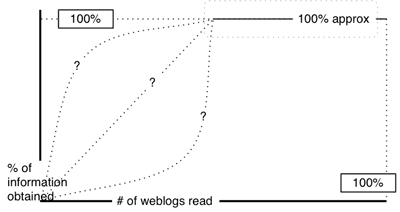
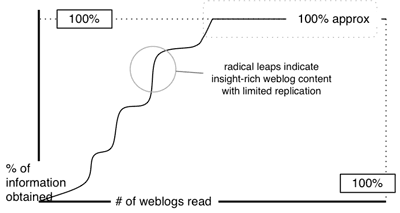
A few days ago a stunningly interesting article was published on Microdoc News called Dynamics of a Blogosphere Story which aimed to look at exactly how a story or discussion moved through weblog space. I’ve been thinking along similar lines for a while now – at least partly as a way of articulating my problems with the iWire Scaling Clay Shirky piece. I’ve been trying to put down on paper why I think the iWire assertions are incorrect and to develop an alternative model of how discussion can occur usefully through the ‘blogosphere’. In fact more than that – I wanted to illustrate why I believe the system works to actually generate better discussion than a simple discussion board – by (on average) helping to hide the bad content and making it easier to find the good content. I most recently wrote something that gestured in this direction (How do we find information in the blogosphere?)
The Microdoc News piece is particularly illuminating because it’s dragged some actual examples into the fray. After examining 45 “blogosphere stories” they found four kinds of posts and a relatively predictable pattern of their usage, with an initial weighty post generating an explosion of smaller fragmentary reactions, commentaries and votes (cf Casting the microcontent vote). These posts are then aggregated or collected into another weighty post, which itself might have the potential to push forward the debate. Their four example posts are:
- Lengthy opinion and molding of a topic around between three to fifteen links with one of those links the instigator of the story;
- Vote post where the blogger agrees or disagrees with a post on another site;
- Reaction post where a blogger provide her/his personal reaction to a single post on another site;
- Summation post where the blogger provide a summary of various blogs and perspectives of where a blog story has got to by now.
I’ve been working in similar directions as this – in an attempt to resolve the questions, “Can you have good discussion across the blogosphere?”, “What is the nature of that discussion?” and “How does it differ from message-board conversation?”. And I think the answer lies – yet again – in going back to the beginning and looking at the way the web in general (and weblogs in particular) operate like an academic citation network.
The origins of the web are highly academic in origin. So it’s hardly a surprise that the combined use of hypertext and discreet blocks of content comes to mirror academic citation in research papers. Apart from a few wry-eyebrow-raising academics, I think most of us would agree that the idea that useful debate cannot happen in academic discourse is patently absurd. After all, the vast bulk of academic research in both the humanities and sciences is published as part of an ongoing conversation involving statements and citations.
The weblog sphere has taken on a great many of the characteristics of the distributed academic community’s citation networks – just at a much smaller, faster and more amateur level. Consensus can emerge (briefly or otherwise), reputations are made (deservedly or not), arguments occur regularly (usefully or otherwise). Nonetheless, discussions do occur, they do progress and they do reach conclusions. But it’s happening at a granularity of paragraphs rather than articles. It’s happening at a scale of hours rather than months.
The Microdoc article could easily have been written about citation networks in academic literature. And when we realise this, then lots of other things become clear too. The answers to my earlier questions are beginning to come into focus. And they remain basically simple answers too:
- “Can you have good discussion across the blogosphere?”
There are clear analogues for the way discussion over the blogosphere operates. One of those is academic / scientific discourse. This suggests (although it doesn’t prove) that not only can we have good discussion over the blogosphere, that it was almost optimised in such a way to make it inevitable.
- “What is the nature of that discussion?”
Perhaps we can answer that now by comparing the Microdoc article with studies of academic discourse like Kuhn’s Paradigm Shifts.
- “How does it differ from message-board conversation?”
If we know what the answer to the previous question is, then maybe we can answer this one by a simple direct comparison.
So here’s my suggestion of how we can usefully conceive of discussion occurring across the blogosphere (and I think it’s a model that’s practically explicit in the Microdoc article, so forgive me if it’s boring). We should think of it as a kind of micro-paradigm shift – a kind of hyperactive academia, where discussion moves forward in discontinuous chunks – with an initial weighty post articulating a position that is then commented upon, challenged and cited all over the place. But the debate doesn’t move forward until someone manages to articulate a position of sufficient weight and resonance to shift the emphasis of the discussion to their new position.
The weight of these debate-structuring posts can often be measured in terms of aggregated insight – in which case it’s a purely progressive model – an individual synthesizes all the interesting comments made by everyone else and pushes it slightly further, generating a new baseline from which the conversation can continue. On occasion, however, it would still be possible that an individual’s reputation would be weighty enough that everything they say defines the scope of the debate – that smaller dissenting voices would not be heard – and the debate would be carried behind a leader of some kind. And of course there are the times where a debate fragments or polarises, where more than one of these structuring posts occurs roughly simultaneously, or with radically different views – bifurcating any debate. Nonetheless, debate remains a series of discontinuous leaps, structured by impactful posting.
Here’s a diagram that I think illustrates how I think discussion happens between weblogs:
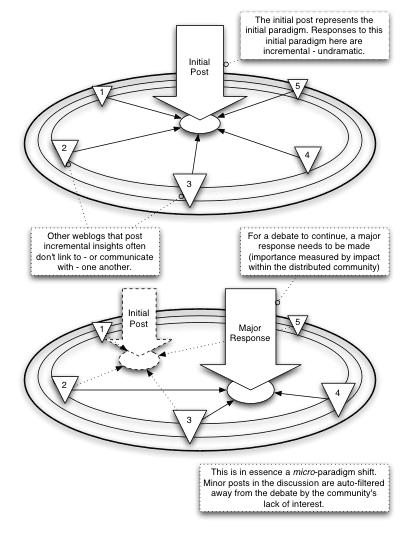
This ties in well with my previous article on finding information in the blogosphere. Because the smaller posts with negligible insight, voting or replicated insight are less likely to be linked to, then they’re also less likely to be read. And yet their value remains – they represent the arbiters (in a distributed fashion) of what should be being read. The posts that one is directed to most quickly are these structural posts – places where some kind of micro-paradigm shift has occurred.
I’m going to end now with a bit of a brief discussion about the differences between this kind of debate and the kinds of discussion that one finds on message-boards. I’m going to start off with a comparative diagram:
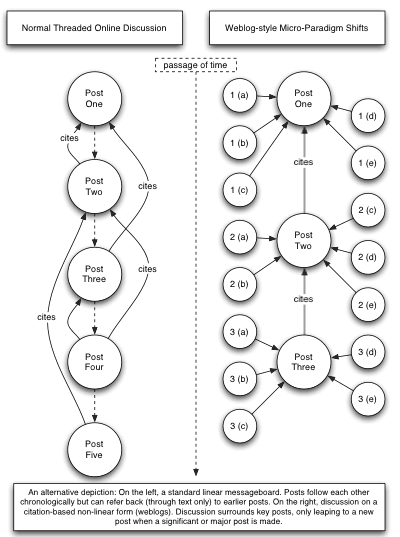 On the left, you can see a normal piece of discussion – as it would occur on a threaded message-board. In this example, the top post is the first, the second post cites the first, the third also cites the first while the fourth cites both the third and the second but not the first. In this debate there is no filtering mechanism of any kind. If the second post is entirely off-topic or contains spurious information, then it remains very clearly in the context of the thread. And if that thread is linked to from elsewhere, there can be no simple evaluation of what posts are considered more worthwhile than other1 – the thread is either good or it is not.
On the left, you can see a normal piece of discussion – as it would occur on a threaded message-board. In this example, the top post is the first, the second post cites the first, the third also cites the first while the fourth cites both the third and the second but not the first. In this debate there is no filtering mechanism of any kind. If the second post is entirely off-topic or contains spurious information, then it remains very clearly in the context of the thread. And if that thread is linked to from elsewhere, there can be no simple evaluation of what posts are considered more worthwhile than other1 – the thread is either good or it is not.
On the right, you can see a simplified diagram of the passage of a discussion through a citation network. If there are filtering mechanisms functioning through the community (in our case people choose who to link to based on whatever personal preference they wish to express) then the most important structural posts will self-locate towards the middle, generating a clear (almost linear) movement of discussion from first principles towards a conclusion of some kind. The conclusion itself may never be met – consensus may never be fully reached – but positions with regard to this evolving dominant narrative will be reached by everyone. Those posts which are merely “I agree” or “I disagree” will be filtered from the public consciousness, even as they have fulfilled a valuable function in directing people towards the next structural post in their debate.
So – what does this all mean? In essence I’m arguing that debate across weblogs self-organises in a pretty useful way. But I’m not going to pretend that it operates perfectly or that we can’t do anything to improve it. However, it seems to me that rather than bemoaning the things that make debate across weblogs different, we should be trying to grease the wheels of those mechanisms. It’s my personal belief (and one that I’ve expressed before) that things like trackback and Daypop work so well because they are specifically building upon – enhancing – the mechanisms that make webloggia operate effectively in the first place. If you’re looking for more specific suggestions, then I think that a balkanisation of blogdex would help different those mechanisms work more effectively within smaller communities with different and more distinct interests. After that, I have no idea. That’s where you people come in…
Footnote: (1) Obviously Slashdot has made gestural moves in this direction, but there are some interesting differences between the way the distributed community of webloggers evaluate one another and the way it is handled on Slashdot.